Zero-Touch Algorithm Handoffs: How We Ship ML Algorithms to Prod Without Rewrites (or ML Engineers)
TLDR;
ML Algorithm integrations were (for us) a frustrating experience of re-implementations, duplicate work, and endless back-and-forth.
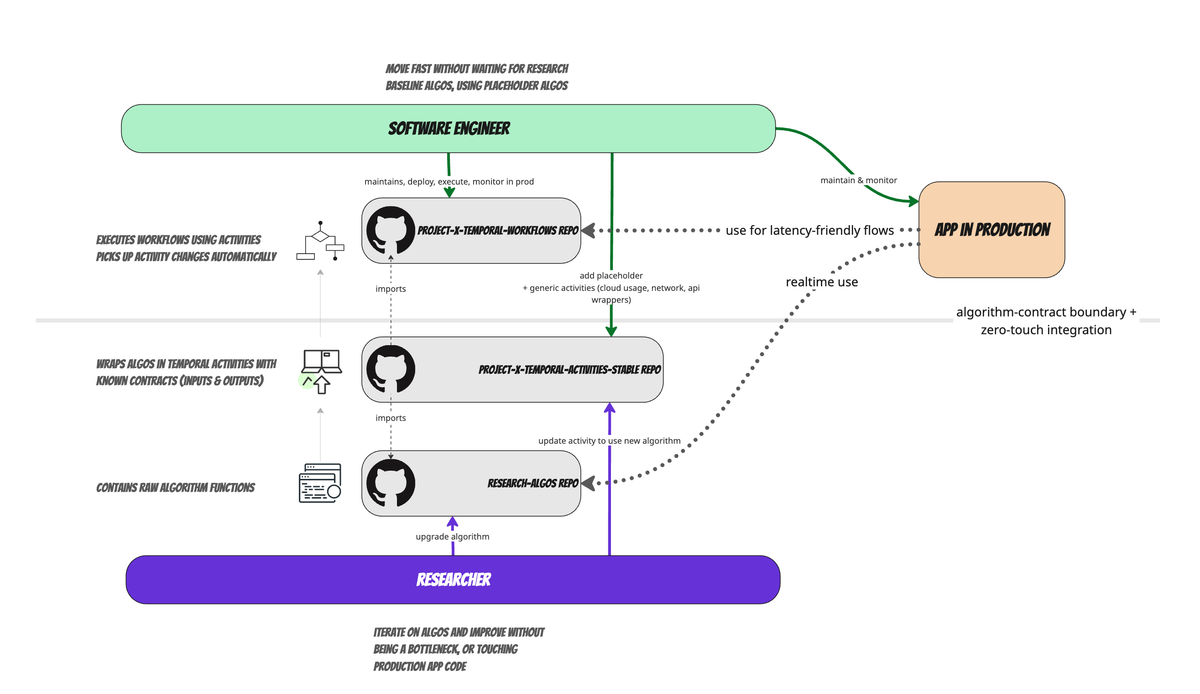
We cut through that by abstracting research algorithms under Temporal activities and letting workflows that run them be maintained by developers.
Researchers push new algo-code, apps just call a workflow that auto updates to latest version of algo. Zero-touch, no ML Engineer babysitting, and production gets resiliency and scale for free.
AI Disclaimer
AI was not used in writing this article except for generating the TLDR section (which I still went through and edited a bit after pasting). However it was used for checking simple typos and mistakes post-writing, and then I corrected them manually.
Background
A common problem we were having at Verbit, where I work as chief architect, was that our collaboration between research teams and engineering teams was frustrating. Researchers were having a hard time collaborating on integrating algorithms for ML into our production code. Myself and Rachel Sorek, VP Research at Verbit, sat together and devised a plan on how to solve this. I'm happy to report back what worked for us.
We're talking about algorithms, not ML models
I'm not talking about testing, hosting and promoting off new versions of existing ML models, retrained on modified datasets, within an existing stable pipeline. There are some common ways for handing off new models using model lifecycle tools such as ClearML, SageMaker, MLFlow and the like.
Our problem was more nefarious.
The lifecycle of an algorithm
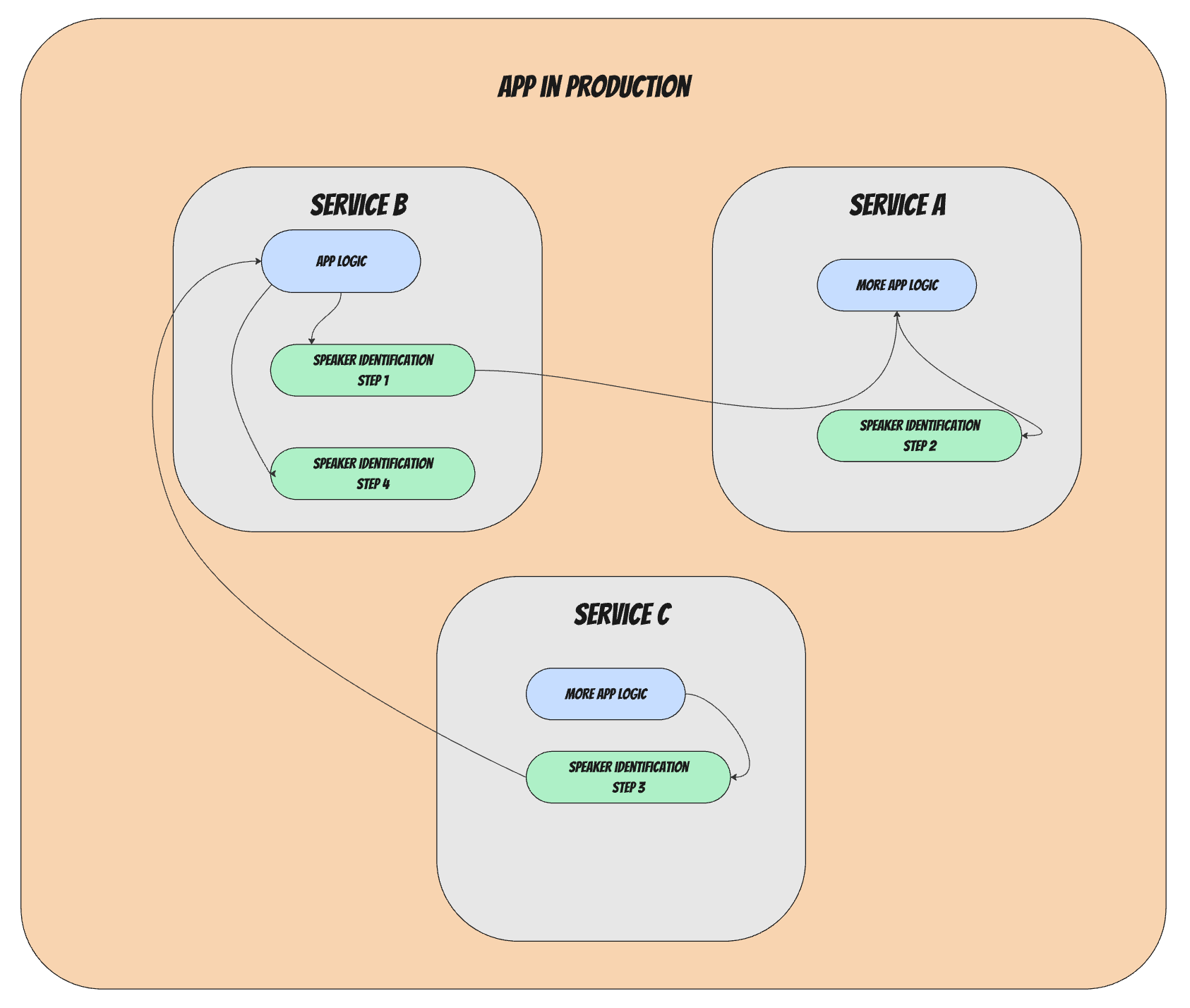
Imagine how an ML algorithm such as "speaker identification"ends up running inside an app.
The following image shows a simplistic view of this.
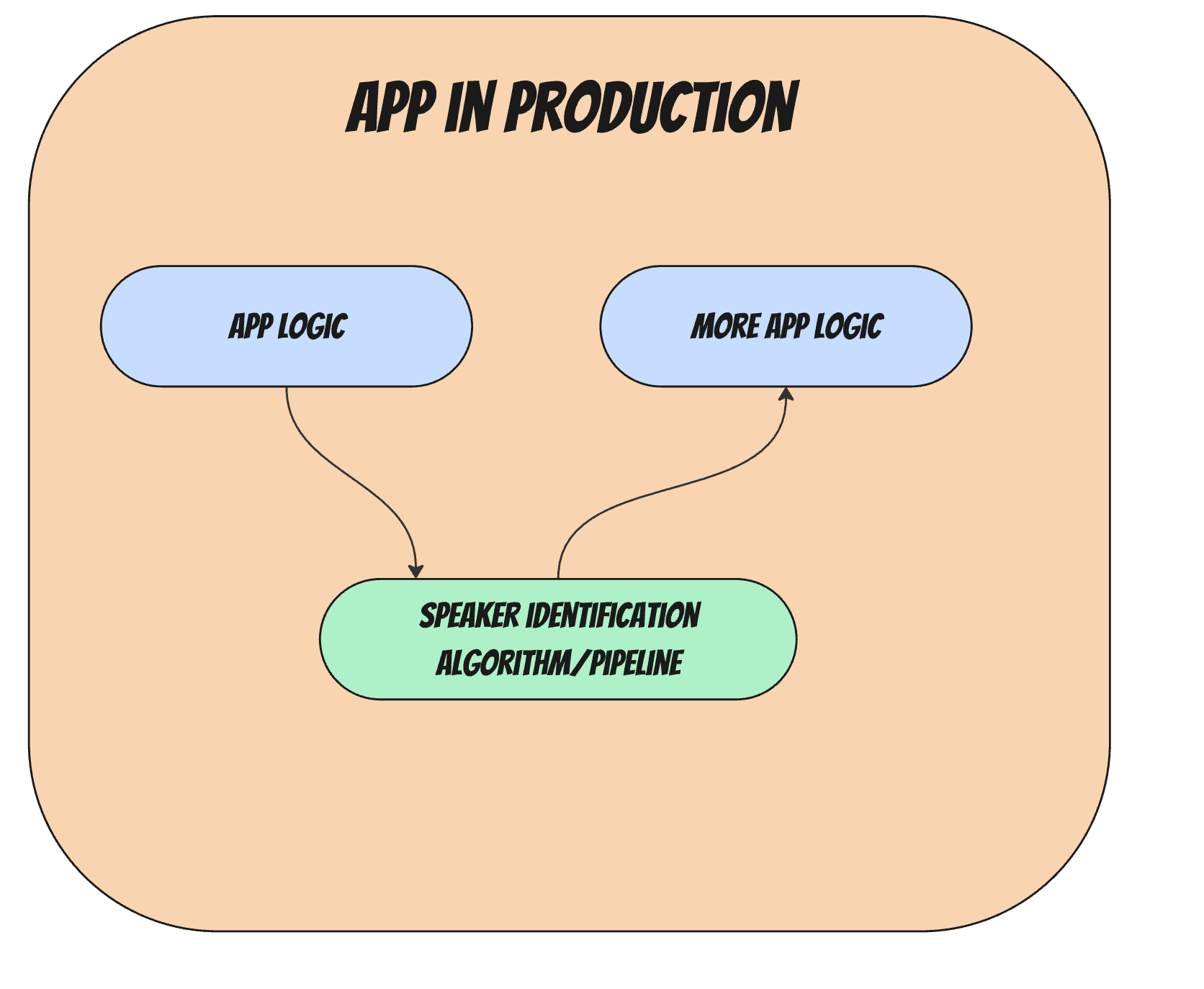
In this simplistic view, some app logic calls out to the algorithm (set of internal steps) that was modeled, tested and created by the research team.The algorithm returns a response to the application's logic. Researchers are supposed to be responsible for the green part in that diagram.
How did that algorithm's code get in there? Let's explore.
The lifecycle of a researcher of an algorithm (round 0)
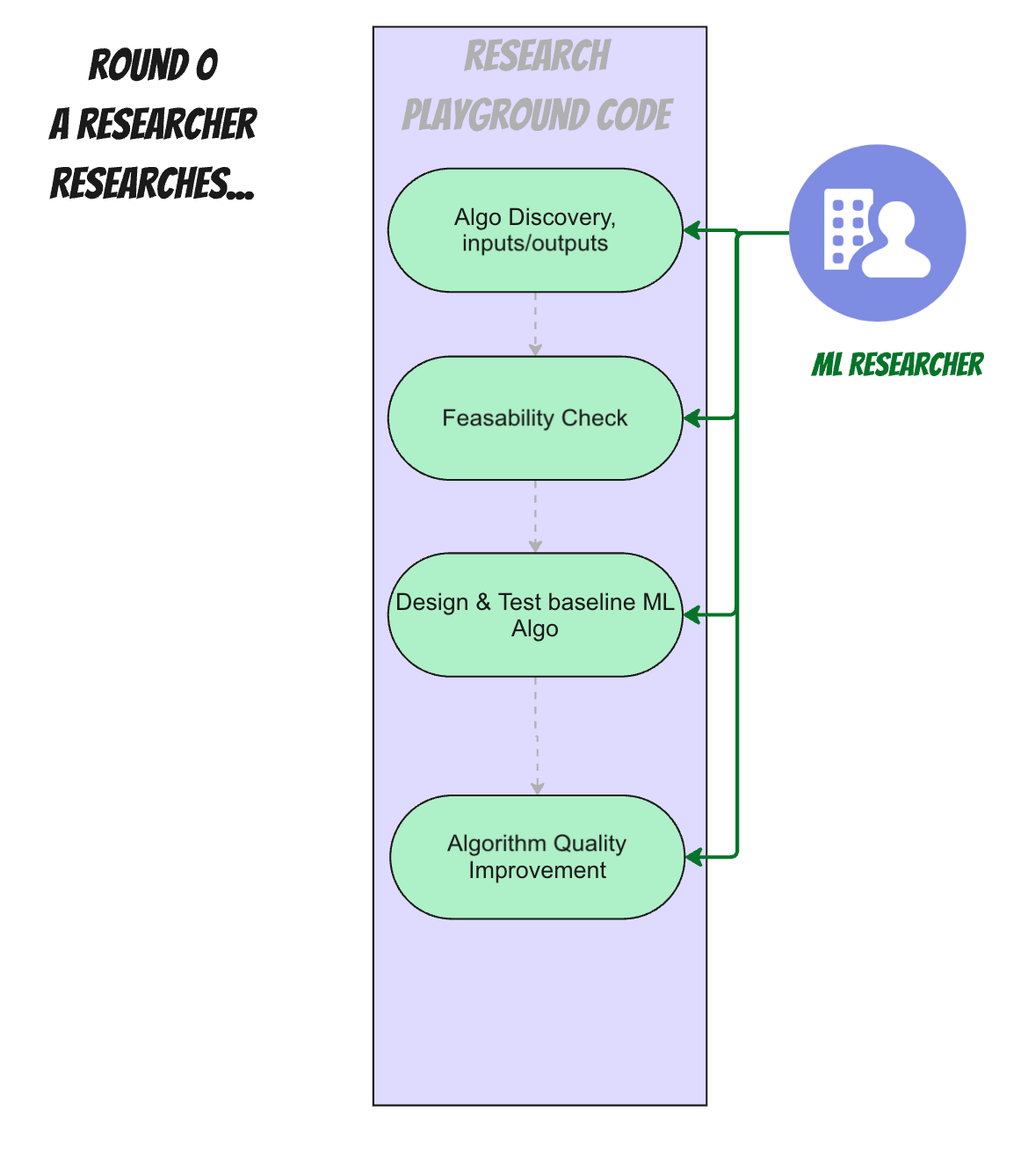
Being left to their own devices, if we didn't need this algorithm running in our production app, a researcher might do some initial discovery on what's required from the algorithm, input and output contracts for the data, parameters and KPIs of success and perhaps do a feasibility check. Then they'll start implementing and creating a baseline (let's call it a "beta" version) of the algorithm that has some real world use.
After that they might tweak and improve the algorithm's quality to achieve improved results based on feedback, either through better input gathering or algorithmic improvements (splitting, chunking, adding "LLM as a judge" or whatever else makes things go better for the expected outcomes).
That's it. There's only one repository in play here (or at least, all code repositories are well known and used by research team exclusively).
Now, we need to somehow integrate this algorithm into the app. Here's a common set of actions our researcher needed to do before:
Integration Challenges - Round 1
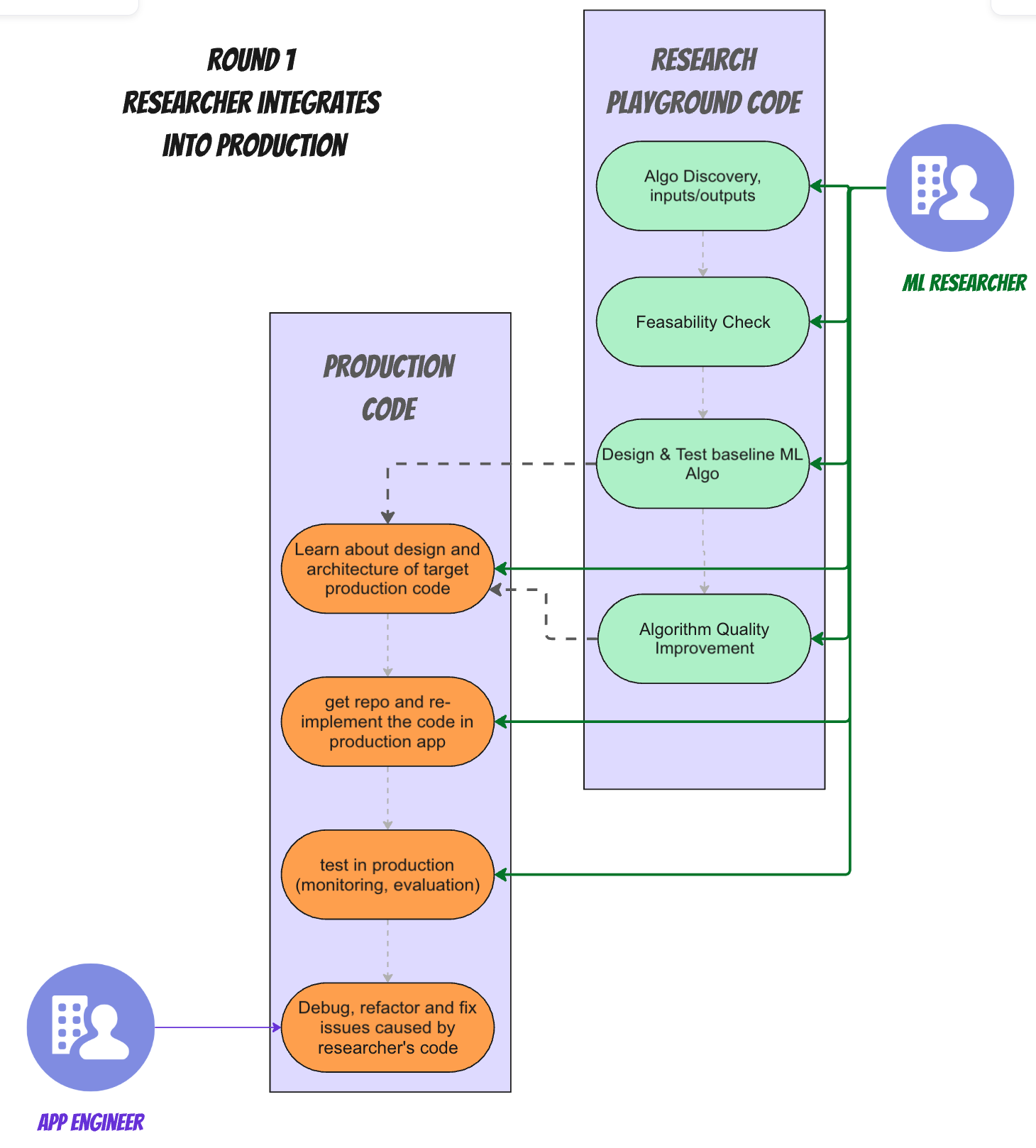
Things get ugly fast when it's time to integrate the algorithm into the production application's source code.
Coupling & Error Prone Rework
- Once the algorithm has been tested at baseline level, needs to be RE-IMPLEMENTED (i.e "lift and shift") - it needs to be surgically inserted into the production code, usually in more than one place (for simplicity I used an example where only one repo needs to change).
- Often there are slightly (or vastly) different dependencies (i.e requirements.txt) for the research team than the production code team that can have differing versions or add new dependencies to the running application's runtime.
This Requires knowing code in the production app's repo - code our researcher usually does not care about and doesn't have enough time to focus on as it's not their "main job". - Over time, the hosting application's code and architecture are not guaranteed to stay static, so lots of re-learning, or even re-adapting the algorithm's inputs and outputs to fit the new app architecture are required. When that happens, we need to change two repositories: the app's code and the research code (so it can be tested with the new input contracts, and vice versa)
- The same is true for the algorithm. Over time an algorithm has to be changed in response to real world feedback. When that happens, we again need to change it in two repositories (at least).
- As bugs get discovered in production and adaptations need to be done, bugs have to be fixed in two places (research playgrounds and production code, while app is running in production)
Skillset mismatch:
- Writing inside a real production app's codebase forces our researcher to live up to the harsher standards of production application code for quality, readability, maintainability, availability, and all the other fun "*-ilities" that one might find in production grade apps. (not that I have anything against it, but at some point they also have to get back to researching stuff.)
- Many times this forces our researcher to also help with production issue handling. This is usually way out of a researcher's comfort zone.
You could just ask an LLM to integrate the algorithm for you, but I wouldn't trust one for such a delicate task just yet, and I'm a heavy cursor user. (The amount of manual lines I've written myself is 0.01% of the total lines I committed this year). I could see this changing in a year, nobody really knows!
Round 2: Enter the ML Engineer
To solve the issues introduced in the previous round, many companies introduced a new role, a sort of "in-between" role that will be able to speak both the researcher's language but also care and know about production application coding standards: the ML Engineer
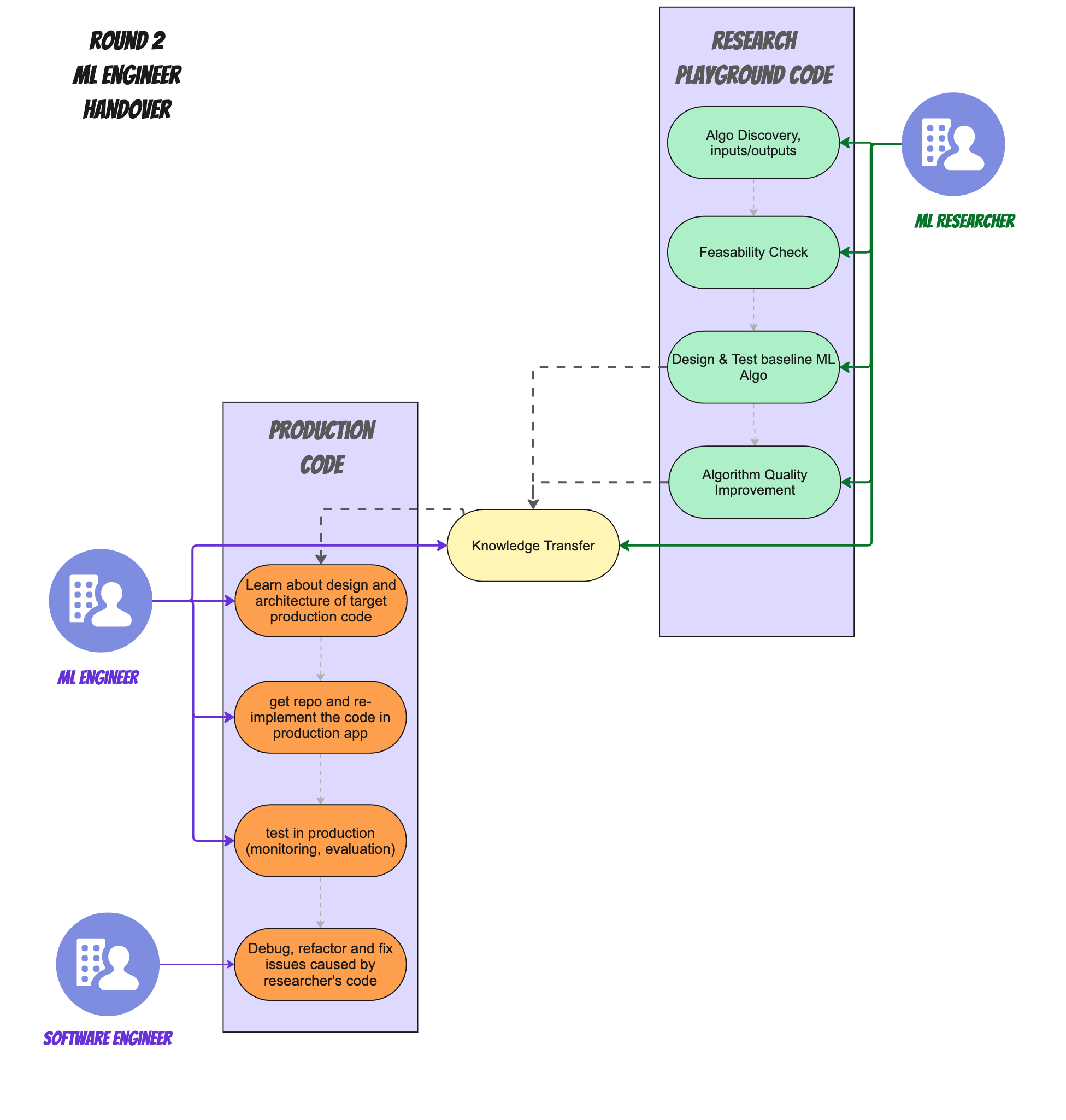
We skipped this part at Verbit and went to round 3, which I'll discuss in the next section, but first - here's how this process might work.
- Whenever there's a baseline or an improved version of the algorithm available, the researcher meets with the ML Engineers and performs a knowledge transfer.
- The ML Engineer is then responsible for doing all the things in the production code that the researcher would have done in Round 1: surgically integrate the algorithm into the app's source code in a way that both doesn't break existing functionality, and also lives up to the coding and reliability standards of the application.
- If there are changes or bugs to fix in the algorithm, lots of back and forth needs to happen so both research and ML engineer are correcting everything on their respective side.
There's another variation of Researcher-->Engineer handoff. In some organizations researchers do the "fun" stuff and ML engineers only do the "boring" integration stuff:
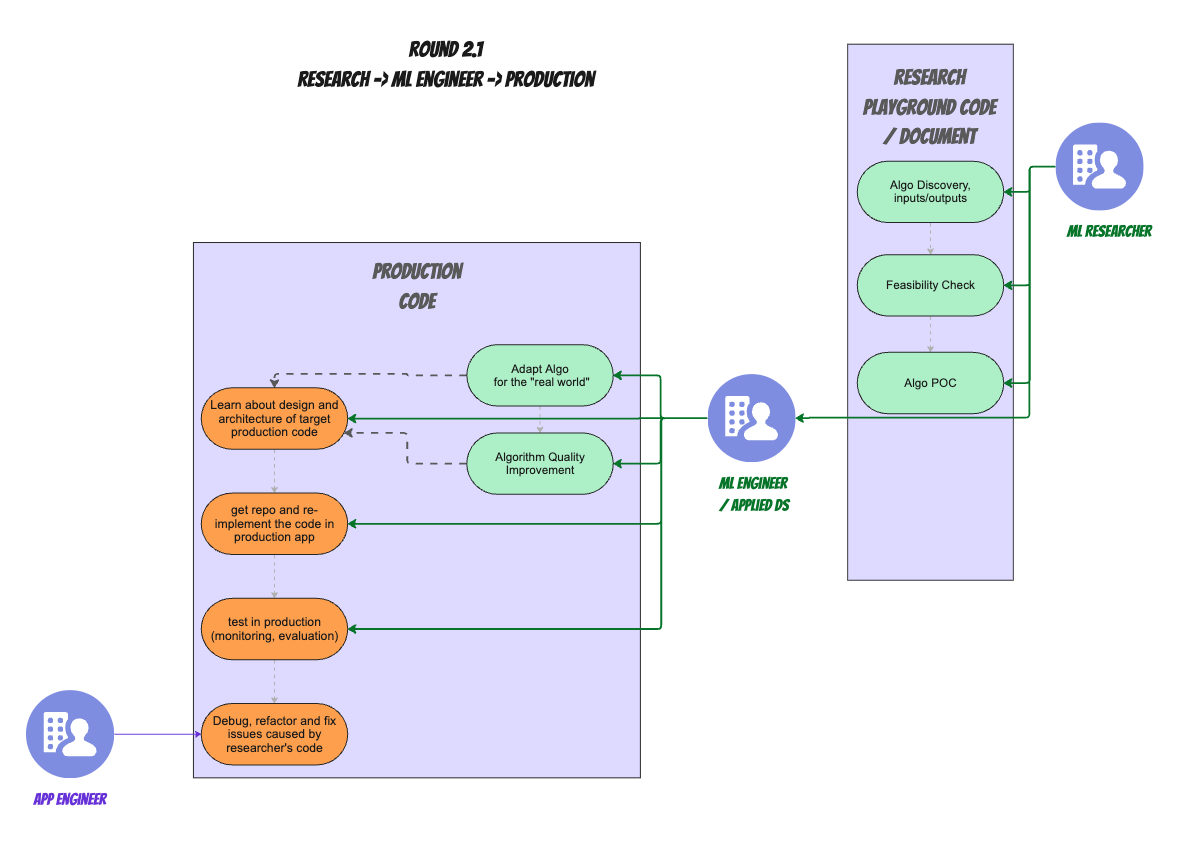
Both of these variations are less than ideal, the way I see it.
ML Engineer Challenges
- Hiring /Training Cost: You now need to find and hire a whole new person to sit in between pure research and application engineers. This costs both time (searching, training, communication overhead) and money.
- Waste: You're still implementing the algorithm multiple times. Basically twice for each revision of the algorithm. You just have a special person that does it now. That's wasteful and error prone and time consuming.
- Knowledge & communication gaps and costs. The more people have to be involved in the effort, the more knowledge has to be transferred, and gaps have to be crossed. This takes time and effort just to communicate, let alone just setting up all those meetings.
- Differing Priorities: In many medium-and-larger sized software companies, researchers and software teams (which contain the ML engineers) are separate teams, with different priorities and different backlogs. An algorithm update could sit and wait patiently for days, weeks or more for the ML engineer's team to have that task in their backlog based on their separate priority queue. At the very least it would take a frustrating amount of project-management-ninja-moves to make sure algorithm updates are done quickly as they surface.
- ML Engineer Dissatisfaction (potentially): ML Engineers, being skilled in both domains might get frustrated at not being able to take a deeper role in the earlier "research" parts of the "research" domain - instead of only taking part in the implementation stage.
Algorithm Spaghetti
The real world is, of course, even more complicated. In reality many organizations have a micro-service architecture, so the integration of the code + algo ends up needing to happen across multiple repositories and team boundaries.
So if we go back to "Round 1" in which our poor researcher was working on their own, the situation looked more like this:
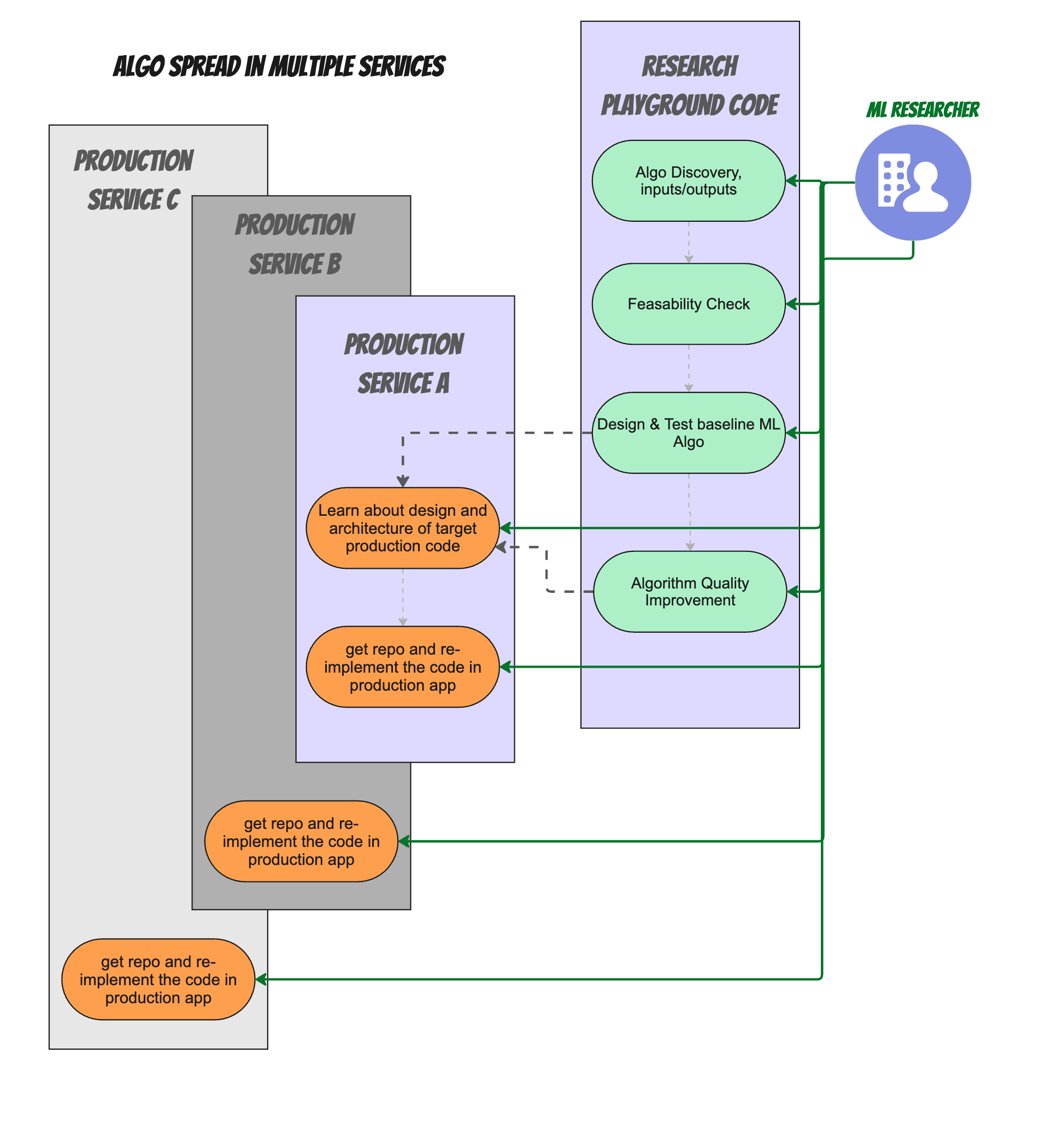
Now multiply all the work that needed to be done for a single repo , across multiple repos, and the issue becomes even bigger. And adding ML engineers into the mix simply compound both the hiring and the knowledge transfer and priority issues, as now all teams represent a dependency to make the algorithm update work:
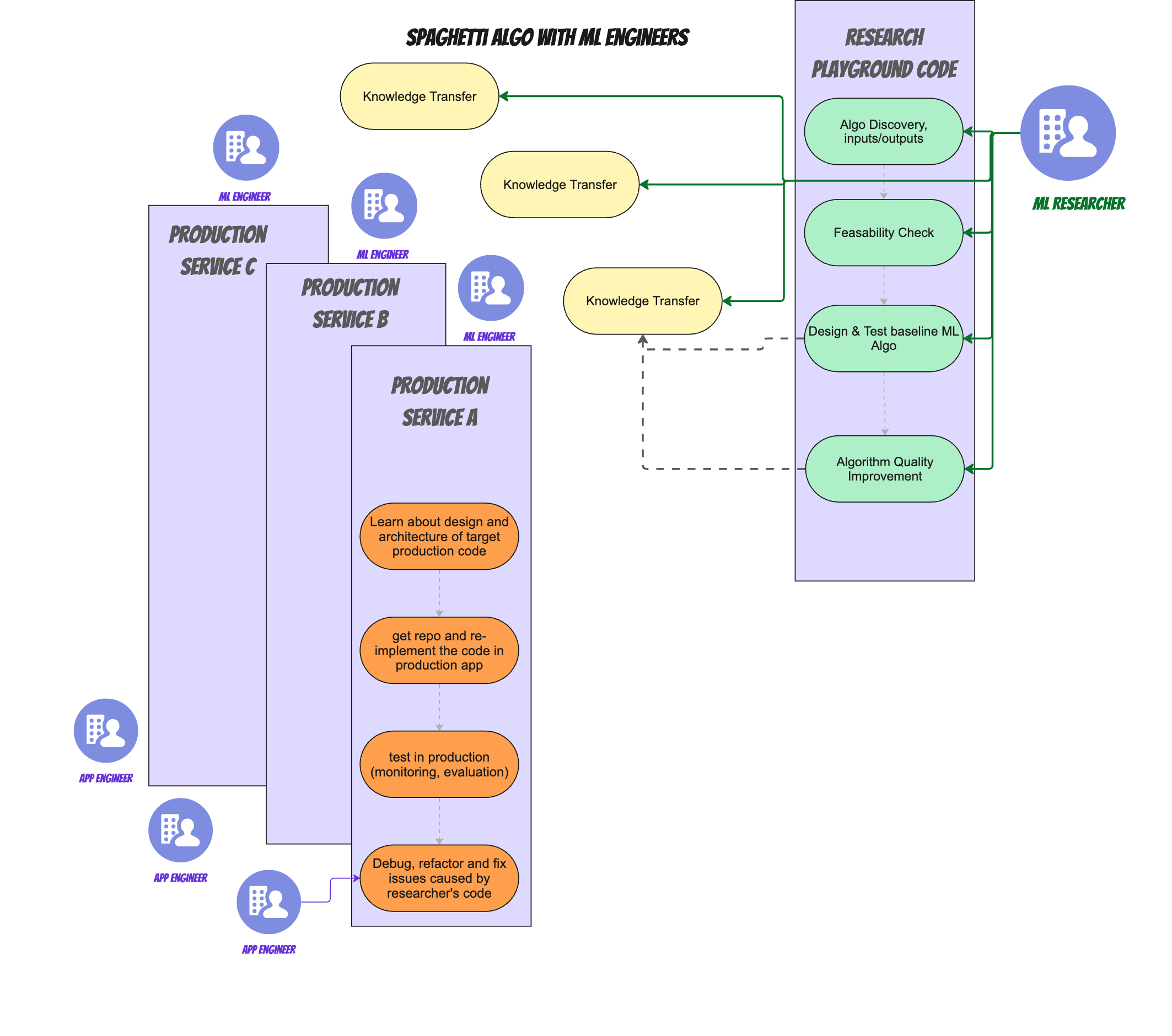
ML engineers might be a smell, but the root cause here (I believe) is that the architecture forces us to create spaghetti algorithms.
Algorithm as-a-service: Wrap it in an API
From a traditional architectural viewpoint, whenever you have some sort of external set of rules, a subsystem which might be maintained by a different team, or that needs to be used by multiple other systems, it is very tempting to just "wrap it in an API and turn it into a micro-service". What prevents us from doing exactly this with our algorithm? (see image for what I mean)
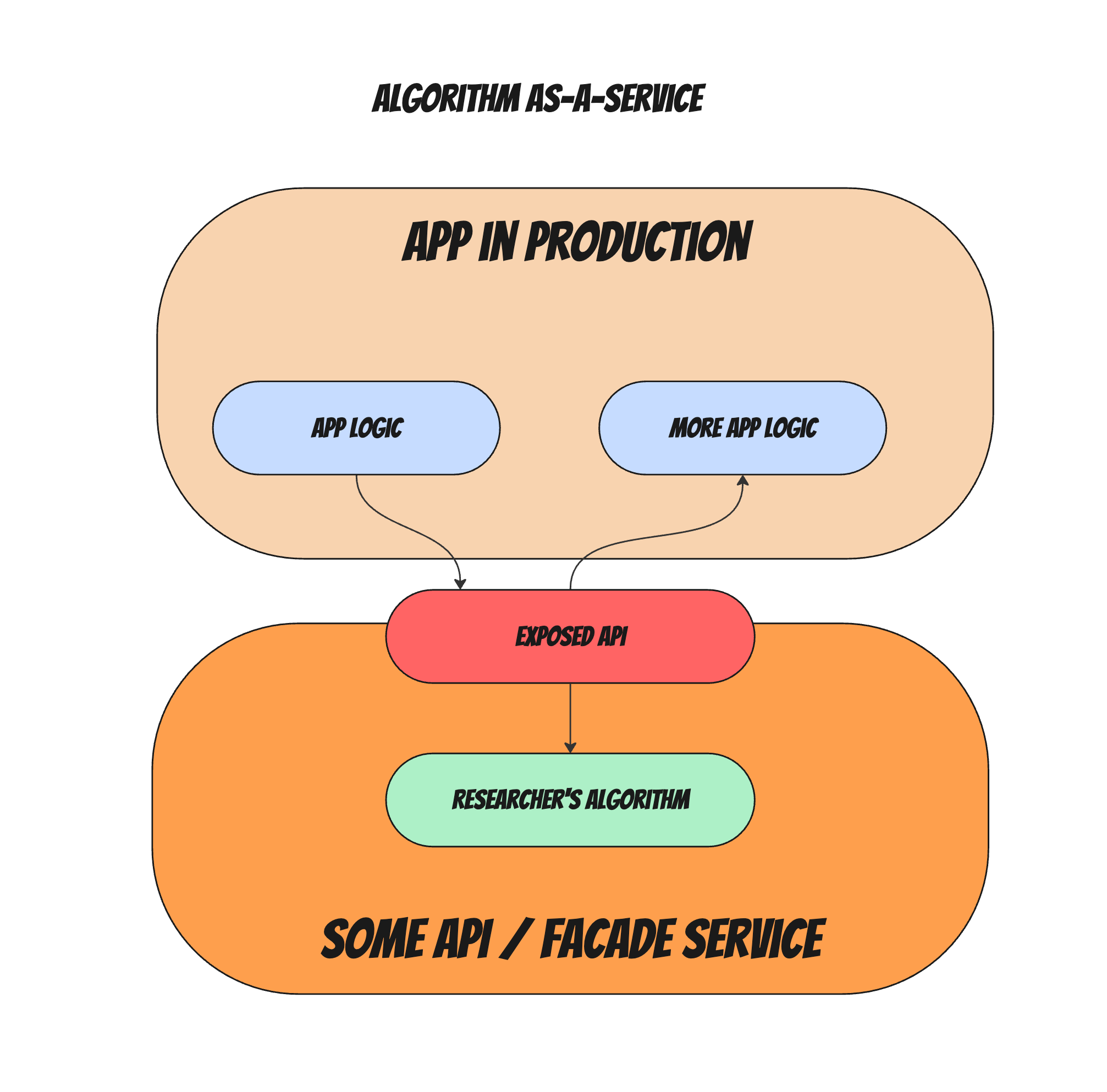
Yes, you could technically expose a new microservice that hosts the algorithm and exposes an API, but:
- Now you have to find someone to code that new service
- deploy it
- maintain it
- monitor it
- document the API
- And so on.
What team owns that new service? Do you develop such a new micro service per new algorithm (adds up to lots of small services in the future)? Maybe you develop one generic API service that exposes ALL algorithms (more complicated and becomes a centralized infra challenge at the company for scale and monitoring)?
In non production use cases you might argue that this would be called "a pipeline", and you might use a tool like AirFlow,AirByte, N8N and the like to make it happen.
But these are production workloads. They might need to happen at a large scale, with high resiliency and in some cases with a specific timing SLA (though what I'll show will be less effective for "real" real-time usage)
Who's going to write that? Not our poor researcher. They had enough work earlier, now they have to maintain a whole new service? (maybe even many such services, i.e one per algorithm). Not our app developer, they have their own app to write and maintain, with their own set of priorities.
No. We need to find a way to get the benefit of exposing the algorithm as an API, but not take on the burden of maintaining all the surrounding infrastructure.
Enter Temporal
Temporal is an example of a tool that offers us the in-between:
- Allow exposing a set of actions as a workflow that is scalable and resilient,
- Also expose it as an API so we can trigger, query, and signal the workflow via external services.
- Allows reusing existing code , so we do not have to rewrite our algorithm, just "import" it into the workflow
- Allows coding the workflow very easily so it can be maintained by app developers with minimal effort (set it and forget it)
- Its architecture lends itself to what we're trying to do here: separation of concerns with very little overhead upfront.
- Allows developers to easily create placeholder activities to stand in place for production use cases until such time when research 'upgrades" them with real or better functionality incrementally over time, thus removing the bottleneck of waiting for research to finish even a baseline algorithm before shipping some beta version into production or dev environments.
This can speed up iterative incremental development for a team and allow engineering and research to work in parallel while still delivering incremental value into production and getting feedback from product or real customers.
Researchers are free to "upgrade" the algorithm in production without waiting for approval from engineering, and can monitor the algorithm by monitoring the workflow in Temporal.
Learn more in Temporal docs
I'll let temporal talk about themselves, and spare you my copy-pasting-fu, go here to read more.
In a nutshell, temporal is to production workflows what N8N, airbyte and other workflow engines are for offline and batch use cases - i.e it can do everything they do, but also do things at high scale, high resiliency and good monitoring. We've been experimenting with them for the past year or so and are pretty happy with the results (I am not affiliated with them, just a happy user so far).
Here's how our algorithm would look hosted inside a temporal workflow:
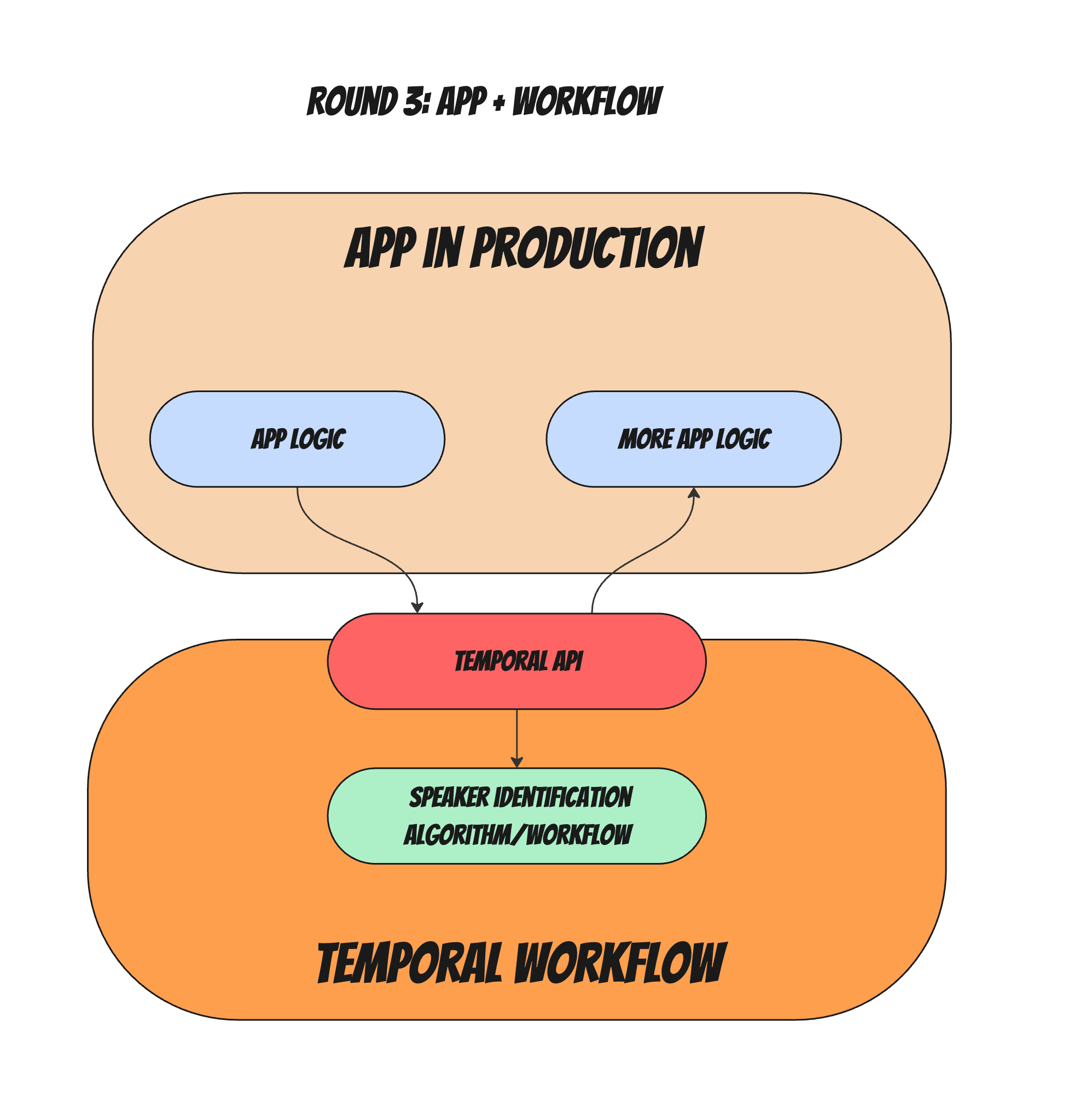
What can we observe?
- The algorithm's code will no longer be part of the application. It now has clear separation boundaries (inputs and outputs)
- Invoking a workflow is basically an API call to temporal with an ID of the workflow, and workflow parameters (plus other stuff which is not relevant for this discussion), we've essentially turned our algorithm into its own little micro-service, which has an API, and can also be signaled and queried for status or state. (in a traditional micro service, each of these abilities "costs' us with a new API creation that has to be maintained and documented, monitored, and tested).
- We inherit Temporal's resiliency, scale and retry mechanisms so we don't have to force our researchers to worry about it.
Workflows are the services, and Activities are the algorithms
In temporal you define a workflow as a code class or function based on their SDK. Workflows are all code based, no fancy designers, and you get to use your favorite language to build them (python in our case).

Workflows invoke activities, which are the actual steps that happen inside the workflow.
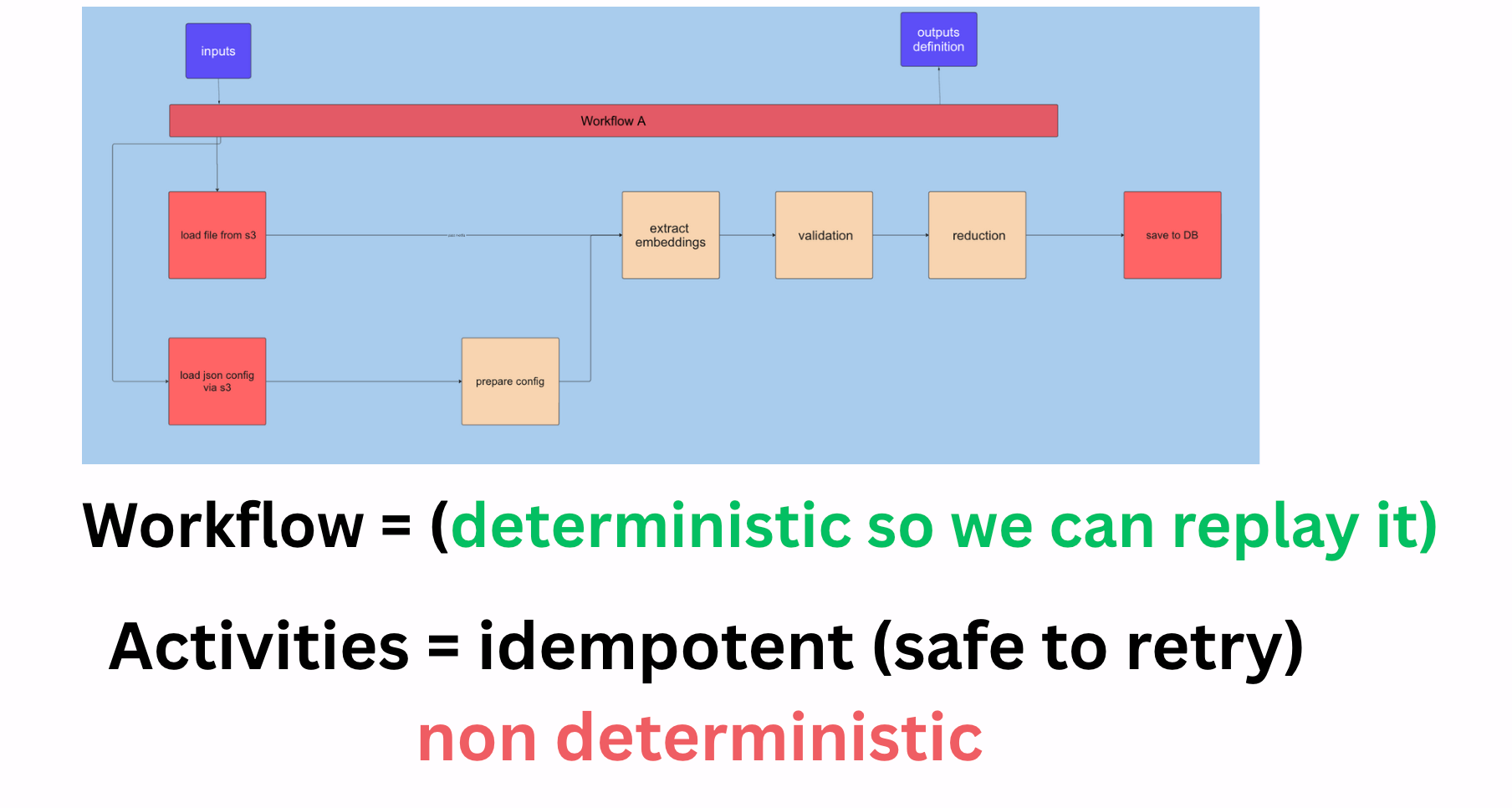
Calling an API , an LLM, saving to a database, reading a file, or anything that might take a long time or might break, all these will happen inside one or more activities which is just a function you import and invoke. Activities are non-deterministic, i.e they might return a different answer every time, might fail or timeout. As a rule, we do want to make sure activities are idempotent - i.e safe-to-retry.
Workflows: Maintained by App Software Engineers
What's more, there is a clear separation between the code of a workflow, and the code of an activity.
Workflows and Activities define data contracts: the definitions of inputs and outputs that have to be passed to them, and those are then used by the calling application.
Here's a simple basic workflow, that we can ask our app-engineers to create - it's really simple and they don't need to know anything about calling our algorithm except the data contract, which is just passing in a name of type string as an input, and returns an output string.
from datetime import timedelta
from temporalio import workflow
# Import activity, passing it through the sandbox without reloading the module
with workflow.unsafe.imports_passed_through():
from activities import speaker_identification
@workflow.defn
class SpeakerIdentificationWorkflow:
@workflow.run
async def run(self, name: str) -> str:
return await workflow.execute_activity(
speaker_identification, name, start_to_close_timeout=timedelta(seconds=5)
)Activities: Maintained by Researchers
On their side, researchers will wrap their algorithm with a simple activity function, that invokes it. If the algorithm has multiple steps that require invocation at different times, then each one will be wrapped with an activity function that can be later invoked by the parent workflow. An activity's data contract is defined by its function signature. Here is speaker_identification:
from temporalio import activity
@activity.defn
async def speaker_identification(name: str) -> str:
return f"Hello, {name}!"
Connecting the dots
Here's the basic flow in real life for us:
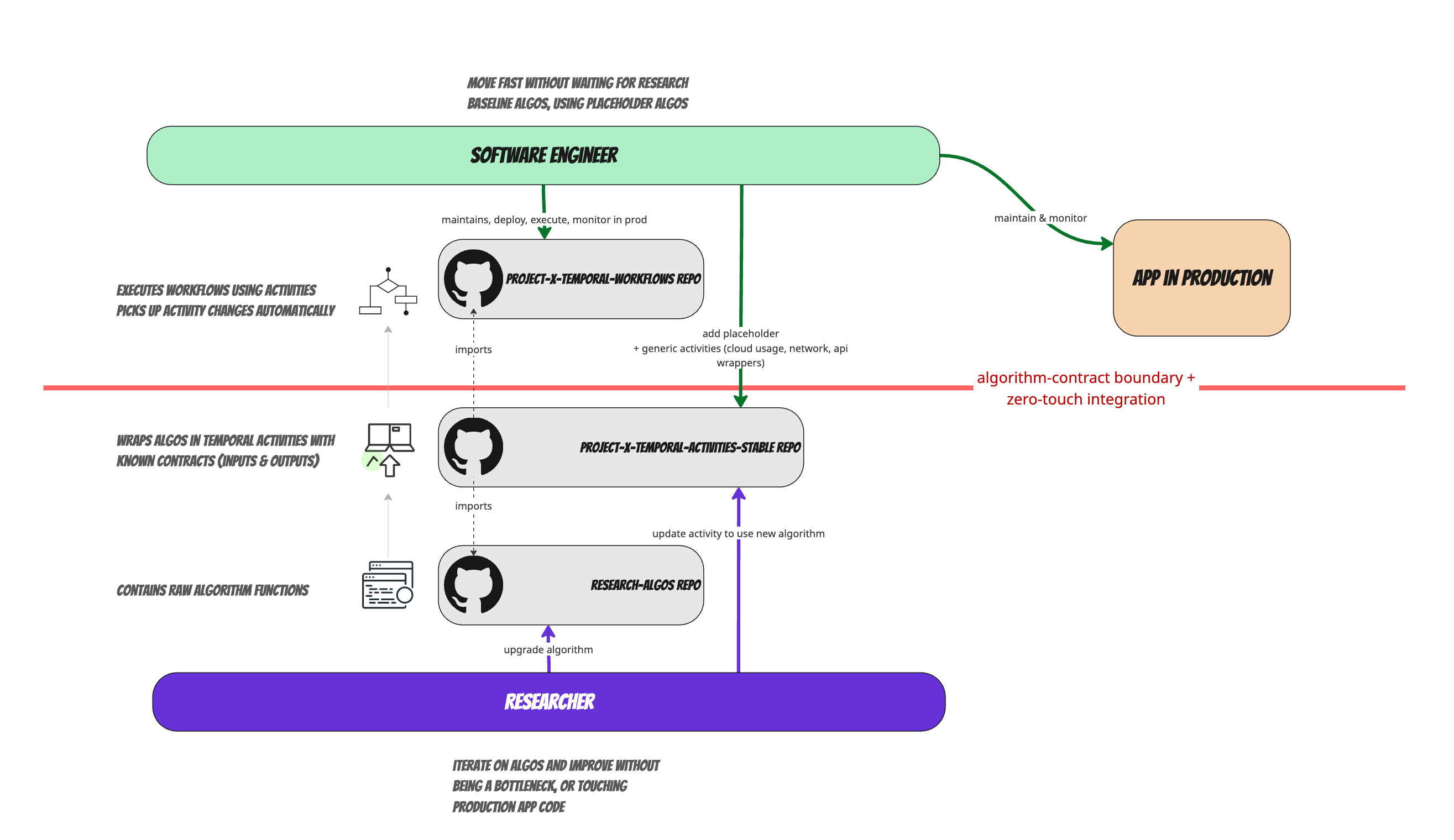
Researchers
- Develop or update an algorithm in their algorithm repository which they control
- They wrap or update a temporal activity in a special "stable-algo-activities" repository that hooks into this algorithm (this is usually less than 10 lines of code)
- They commit and push the update into GitHub
- That's it!
Temporal Workflow (maintained by App Engineer):
- Auto-imports and picks up the new activity version
- When invoked will import and trigger the latest version of the activity , and thus the algorithm
- Is a "set it and forget it" workflow, once it works, unless there are major new algorithm steps or activities to include , does not need to be touched, and will keep using new versions as they are pushed by research team, without human intervention
- Can be as small as 20 lines of code in some cases, and is just a set of function calls to activities in a specific order.
App Developer
- Maintains the workflow code , which is very simple
- Does not need to worry about researcher code, only about invoke the activities, which have well defined inputs and outputs
- Takes care of resiliency and scale parameters (configuring the Temporal workflow declaratively) , but overall knows nothing about the algorithm. It is fully abstracted away by the activity(ies)
And here's a visualization of this process:
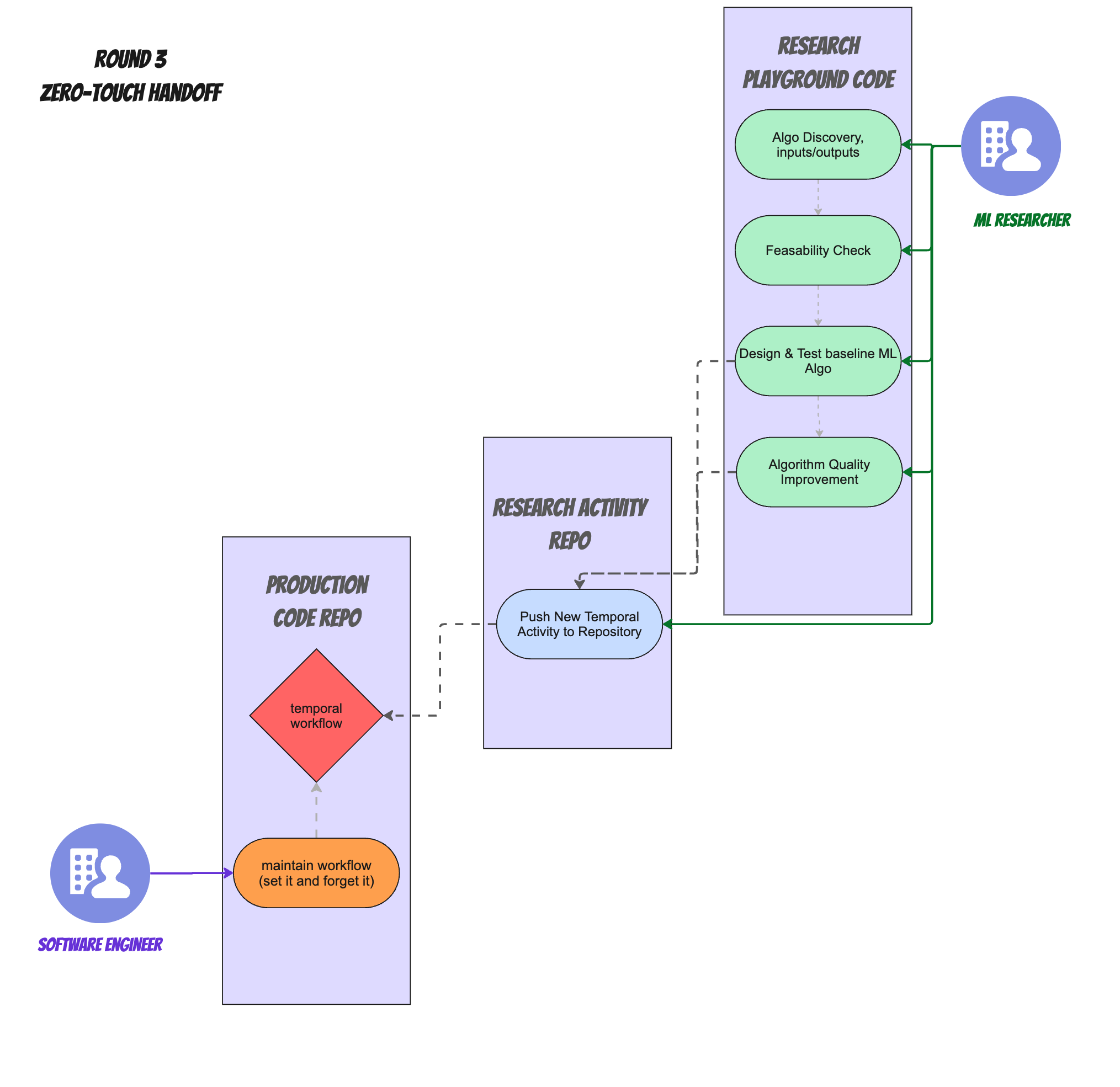
Multi-Service structure with a workflow
When you have multiple services that need to use or invoke parts of the workflow, all those services need to do is communicate with the workflow via API calls, sending signals or queries to it. See image:
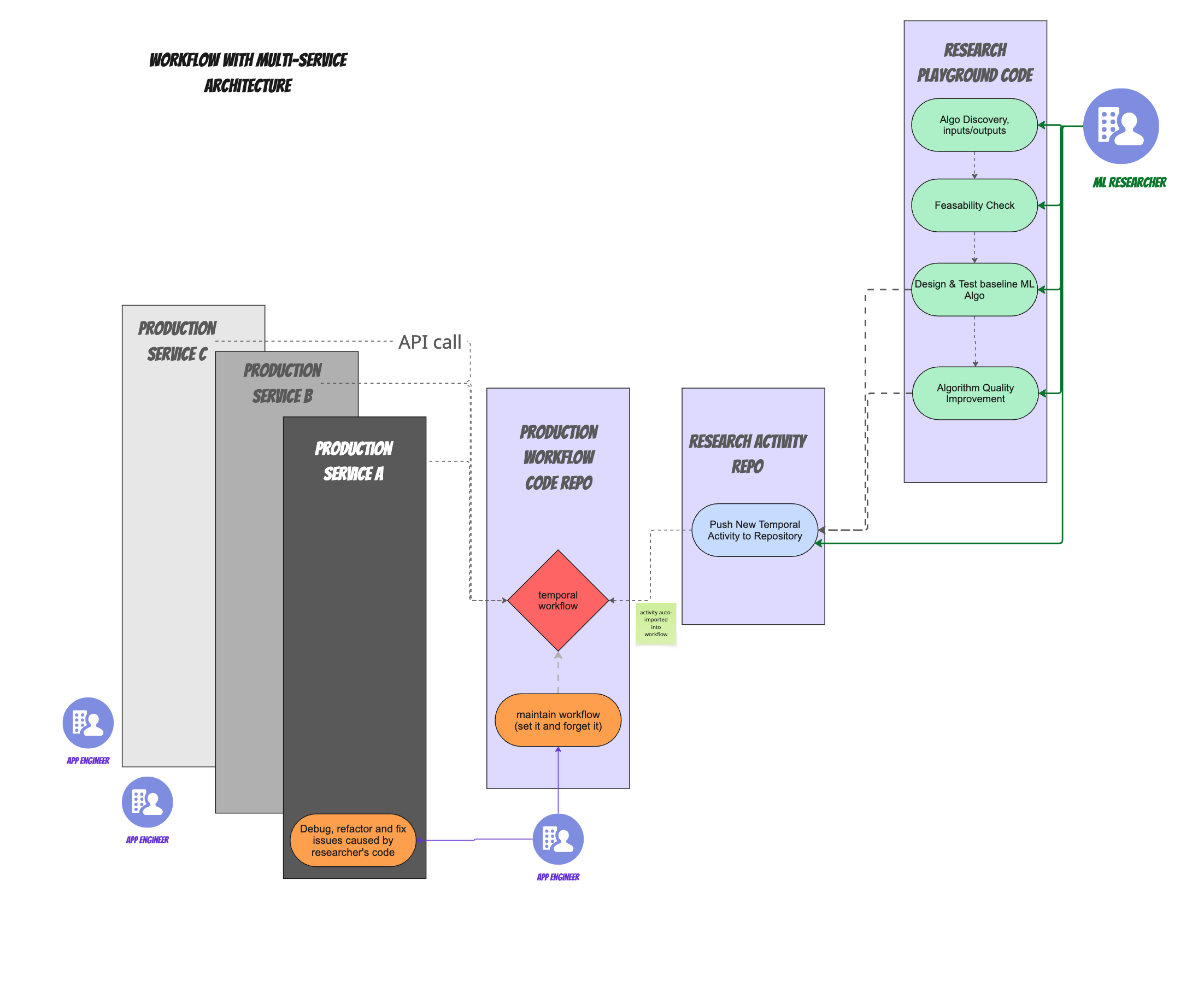
Note that in the multi-service case, we've added a new repository that holds the workflow, so that we can have a clear separation of workflow code from pure application code (which exists across multiple micro-service repositories, with no clear owner for the entire app) so we end up with the following repos:
- Researcher playground repo
- Researcher stable activity/algorithm repository (in this case also holds the temporal activities, but we are considering splitting that up into activities repo and stable algorithm repo )
- Production workflow repo
- The various micro-service repos
We are essentially using repositories as a point of abstraction and separation of responsibilities across different teams, and not requiring people to work on other team's repos, only on their own.
Summary
Pros:
- Real zero-touch: barring huge changes to the algorithm (new steps, new inputs or outputs), there is zero touch handoff. Developers do not need to know or care that a new algorithm version has been deployed (of course they should be notified!) but they do not need to "do" anything about it. The infrastructure takes care of 95% of the cases here.
- Researchers do not need to know how the production code works and operates, only the inputs and outputs of their algorithm.
- The workflows can be monitored and evaluated as a separate entity for future improvements of the algorithm
- Researchers do not need to touch or re implement the algorithm multiple times
- No need for ML ops engineers for this use case!
- Requires a relatively very easy learning curve from developers and researchers. We were able to get people up and going within less than a day.
Cons:
- There still is some learning curve associated with getting things up and running for all parties involved, it's not zero cost, and requires teaching and coaching people, and coordinating efforts and "aligning" on a shared objective. Nothing you wouldn't see at any other cross team tech initiative.
- Requires upfront preparation with standards and running infra of temporal before attempting this. we ended up doing the following:
- Create a proof of concept with Temporal internally
- Create internal GitHub samples repository with pre-configured hello-world workflows that use our infrastructure for deployment (we use terraform) so that when we teach teams and researchers we can give them the code base and point to specific examples they can base their activities or workflows on
- Decide on repo naming conventions beforehand with all relevant parties
- Setup monitoring and auth for our developers and researchers, and setup initial temporal workspaces
- Overall it took us about a month to get the initial setup going, with 1 person working full time on this from our architecture team.
- Then a couple of weeks to get the first POCs running across a couple of teams
Overall we've been pretty happy with how things are working out.
Next Steps
- We're still figuring things out, and will be continuing to experiment with more complicated algorithm interventions such as an offline-online algorithms (i.e algorithms that need pre-processing early, and then run-time processing in real time)
I hope this is useful for others who might need to solve the same issues.
You can reach me here if you want to ask or discuss anything at all.
Some names I'm thinking:
Algorithm Handshake Pattern,
Algorithm-As-A-Service,
Algorithm Gateway Pattern,
Algorithm Conduit Pattern,
Algorithm Bridging Pattern,
Algorithm Facade Pattern
(I'm open to hearing others!)
Comments ()